LLama 2
Introduction: Llama 2 is an open-source large language model (LLM) developed by Meta AI.
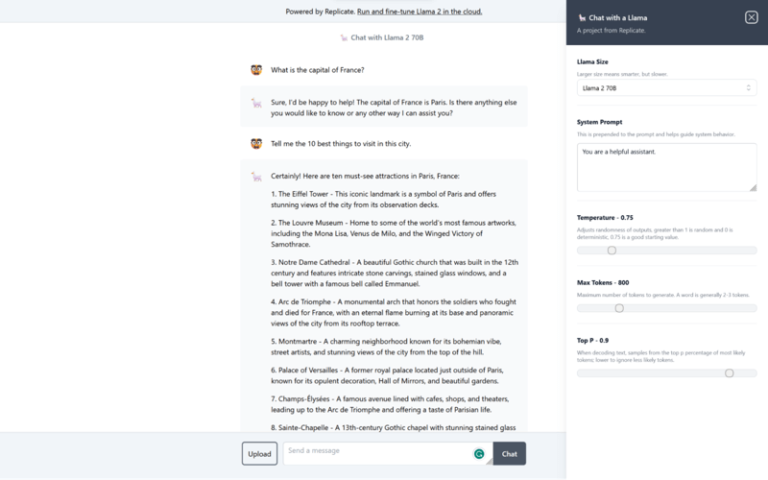
What is LLama 2?
Llama 2 is an open-source large language model (LLM) developed by Meta AI. It has been trained on a vast amount of data to generate coherent and natural-sounding outputs.
Llama 2 outperforms other open-source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests. Llama Chat, the fine-tuned model of Llama 2, has been trained on over 1 million human annotations and is specifically tailored for conversational AI scenarios.
Main Features
- Text Generation: LLaMA 2 can generate coherent and contextually relevant text, making it useful for tasks like writing, summarizing, and translation.
- Understanding Context: The model is trained to understand the context of conversations and can respond appropriately to complex queries.
- Versatility: LLaMA 2 can be used for a wide range of applications, from chatbots and virtual assistants to content creation and data analysis.
- Customization: Developers can fine-tune the model for specific tasks or domains, improving its performance for particular use cases.
- Open Source: LLaMA 2 is part of Meta’s AI Research Lab efforts, and some versions may be released as open-source, allowing developers to use and modify the model.
Pros and Cons
- Technical Improvements
- Expanded Training Corpus
- Safety Enhancements
- improvement in Human Evaluation Performance
- Reduced Commercial Barriers
- Innovation in Safety
- Language Capability
- Inference Gap
- Limited Customization
- Hardware Requirements
- Potential Bias
How to Use LLama 2?
- Access the Model: If LLaMA 2 is open-source, you can access the model through GitHub or a similar platform where it is hosted.
- Set Up the Environment: Follow the instructions provided to set up your development environment, which may include installing necessary libraries and dependencies.
- Load the Model: Use the appropriate code or command to load the LLaMA 2 model into your environment. This may involve downloading pre-trained weights and configurations.
- Interact with the Model: Write code or use an interface to input text and receive responses from the model. You can ask questions, provide prompts, or perform other text-based interactions.
- Fine-Tune for Your Use Case: If needed, fine-tune the model on your specific dataset to improve its performance for your application. This step may require additional computational resources and expertise in machine learning.